Last year I finally decided to learn some Rust. The official book by Steve Klabnik and Carol Nichols is excellent, but even after reading it and working on some small code exercises, I felt that I needed more to really understand the language. I wanted to work on a small project to get some hands-on experience, but most of my ideas didn’t feel very well suited for Rust.
Then I started reading the amazing book Crafting Interpreters by Bob Nystrom. As the name suggests, the book is about writing an interpreter for a dynamic language named Lox. The book is split into two parts: the first one shows how to implement a simple tree-walking interpreter using Java. The second part shows how to implement the same interpreter, but this time using a high-performance bytecode VM using C. I implemented the first part in Clojure, and then I realized that the second part was the perfect project for trying Rust.
The domain of language VMs seems to be almost entirely dominated by C/C++. VMs are very performance sensitive and often require a lot of micro-optimization. This project seemed like a perfect exercise to compare Rust against these languages. I was especially interested in checking if Rust could match the same speed while providing better safety and ergonomics.
Disclaimer: It’s been a long time since I used C/C++, probably more than 15 years. Even then, I mostly used these languages for university projects or some open source contributions. During my entire professional career, I have only used higher-level languages. Consider this post as coming from a beginner.
Now, matching the speed of the C version of the Lox interpreter (clox) is no easy feat. While many books on the topic of compilers and interpreters focus exclusively on explaining the algorithms and leave performance as an afterthought, Crafting Interpreters shows how to implement a really fast interpreter. For example, in some simple benchmarks, it is common to observe that clox is 2x or even 3x faster than equivalent Python or Perl code.
Side note: Take this comparison with a grain of salt. The reason Python and Perl are slower is that these languages provide more flexibility and that comes with a performance cost. This is better explained in Wren’s web page, which is another language by the same author whose interpreter inspired clox. So yes, the comparison with Python and Perl is a bit oranges and apples, but the main point here is that clox performance is really good and very production-ready.
Using only safe code
When I began coding my Rust implementation of Lox, I decided to stick to purely safe code. Rust’s main selling point is its safety, but of course you have to stick to the safe part of the language. Rust also allows you to use unsafe code, and if you do that, I think there is no blocker to match the speed of C, although that also means matching its unsafety. It made sense to stick to safe code to begin with.
I also decided to take advantage of Rust standard library as much as possible. One more interesting fact about Crafting Interpreters is that it does everything from scratch. The book doesn’t use libraries or parser generators or any tool besides a C compiler and standard library (which is pretty bare-bones). Every single line of code is in the book and I find this absolutely amazing. So there are some chapters dedicated to showing how to write dynamic arrays, strings, and hash maps. Given that Rust’s standard library already has those and they are very optimized, I decided to use them and skip a custom implementation. Besides, implementing those manually most likely requires writing unsafe code.
I also wanted to take advantage of Rust’s advanced type system as much as possible. The clox implementation uses variable-length opcodes where most of them use one byte but some use adjacent bytes to pack parameters or data. In my implementation, I decided to use fixed-length opcodes using an enum. Rust’s sum types are a delight to use because the compiler always has your back and warns you if you ever forget to check for a specific case. I consider this a huge advance in ergonomics.
The beginning of writing the lox interpreter in Rust was a breeze. The compiler in particular was a joy to write. Rust felt much nicer to write than the old and quirky C. The initial parts of the VM were also really nice to write thanks to sum types, compile-time checks, and a ready-to-use standard library. However, things started to get very tricky once I worked on more advanced stuff such as closures and classes. The clox implementation uses pointers and aliasing very liberally, while Rust’s aliasing rules are very strict and the borrow checker disallows many patterns to ensure safety. Because of this, I spent a ton of time finding workarounds to make the borrow checker happy.
Side note: Dealing with the borrow checker is a well-known struggle for Rust beginners. This was the reason why I spent so much time here. The rules are simple but for some reason, it’s really hard to keep track of them in a big system. I would often write huge refactorings thinking that they would be a solution to a borrow checker error, just to get another one at the end of the refactoring. This happens less frequently the more experience I get with the language, but it still happens. The book Learn Rust With Entirely Too Many Linked Lists has some good examples of how brutally complex the borrow checker can be.
A garbage collector in safe Rust
By far the hardest part to implement in my safe Rust implementation of Lox was the garbage collector. How do you even write a GC without manual memory allocation and deallocation? I spent quite some time experimenting and trying different approaches.
One quick idea that crossed my mind was that perhaps I could skip the GC completely. If Rust can be memory safe without GC, perhaps I could use the same mechanisms to do the same for Lox. For example, using reference counted smart pointers. But I quickly discarded this idea. The Lox language doesn’t have the strict rules that Rust has; it’s easy to create cyclic data structures that would leak memory if implemented using reference counting. A GC is a must here.
So I got an idea from a very interesting talk at RustConf 2018 by Catherine West. A common workaround in the Rust world to deal with graph-like structures with cycles is to use vector indices as some sort of pointer. I decided to study the code of some popular crates such as id-arena and typed-arena that use this concept in some way. But the main issue with id-arena is that it doesn’t support deletion of individual objects because there is the risk of running into the ABA problem. This happens when you delete an object and later reuse its slot while there is a live reference somewhere, which will then be pointed to the wrong place in the vector. There are ways to solve this issue, such as using a generational arena, but this felt like over-complicating things.
One day I realized something that now feels so obvious that I’m almost ashamed to admit it: I am writing a garbage collector and its main job is to find objects with no references from the live parts of the program. This means that, if my GC works correctly, I should not worry about the ABA problem at all, because the GC would ensure that there will be no live references of the freed objects.
With this idea in mind, I ended up with a very simple design for a GC in safe Rust. It’s basically a vector of trait objects. Every object should implement a trait (GcTrace), which has methods for tracing an object. Additionally, there is a second vector that contains tombstones to keep track of the deleted objects. The allocation of an object means adding it to the vector and returning the index which will act as some sort of pointer. Freeing an object means swapping it out of the vector and putting some placeholder instead, and adding the index to the list of tombstones that will be reused in a future allocation.
Instead of returning plain integers, I also created a generic wrapper struct to get some type safety, so that if I allocate objects of different types, the result index is also of a different type. This is very similar to what the id-arena crate does. This result index is Copy, which means that I can pass it around as I want without getting nagged by the borrow checker. This also facilitated the design of the interpreter quite a lot, as I was able to get rid of many workarounds that I added to please the borrow checker such as using RefCell and Rc. In the end, using the GC looks like this:
// creates an object
let closure: GcRef<Closure> = gc.alloc(Closure { /*…*/ });
Then I can copy and pass around this closure reference everywhere, but when I actually need to do something with the object, I can borrow it from the garbage collector. For example:
let upvalues = gc.deref(closure).upvalues;
This de-reference dance is a bit unergonomic. I have to call gc.deref() every time I want to work with any GC object. I thought that perhaps I could implement Deref and make the Rust compiler do it automatically for me, but this would require each GcRef object to hold a reference to the GC and dealing with the lifetimes would be a nightmare. I could also make the GC completely static, but I don’t even know how to do that with safe Rust only, so I decided to just live with it.
This GC design is extremely simple and it has a bunch of shortcomings. One of them is the fact that the memory needed for the vector of trait objects and the tombstones never shrinks. So if a program suddenly allocates a lot of objects and those are then freed by the GC, the space required for the slots remains there forever. Another shortcoming has to do with when to run the collection process. The GC in clox has precise control of every allocation, and there is a count of the number of the total bytes allocated. When this count reaches some threshold, the collection process runs. In my Rust GC, I can’t have a precise count of the number of bytes allocated because objects often have dynamically sized fields such as strings or vectors. As a workaround, I added a size() method to the GcTrace trait to estimate the size of an object and use it to keep count of the allocated bytes. But this is just an approximation.
Once I was done with the GC, the remaining parts of the Lox interpreter were easy to write. I ended up with a Lox implementation written in 100% safe Rust code and passing the 243 tests from the Lox integration test suite.
Performance
After having a working Lox interpreter and a green test suite to validate any change, it was time to start working on improving performance. At this point I had already abandoned any hope of matching the speed of clox with only safe Rust. As I mentioned before, clox is a really fast implementation and it uses all sorts of tricks to achieve this. From using pointer arithmetic without any runtime checks to the super tricky NaN boxing. However, I thought that if I added a few unsafe blocks to my code base, I could at least come close to the speed of clox.
The first step is, of course, measuring the performance. I decided to use the same benchmark programs available in the crafting interpreters repository. This way of measuring might not be the best, but it’s good enough for a language without any real-world programs. I also decided to manually transpile the benchmark programs to Python and Perl to have some point of comparison. I was expecting some bad results for my very first implementation, but they were much worse than I anticipated:
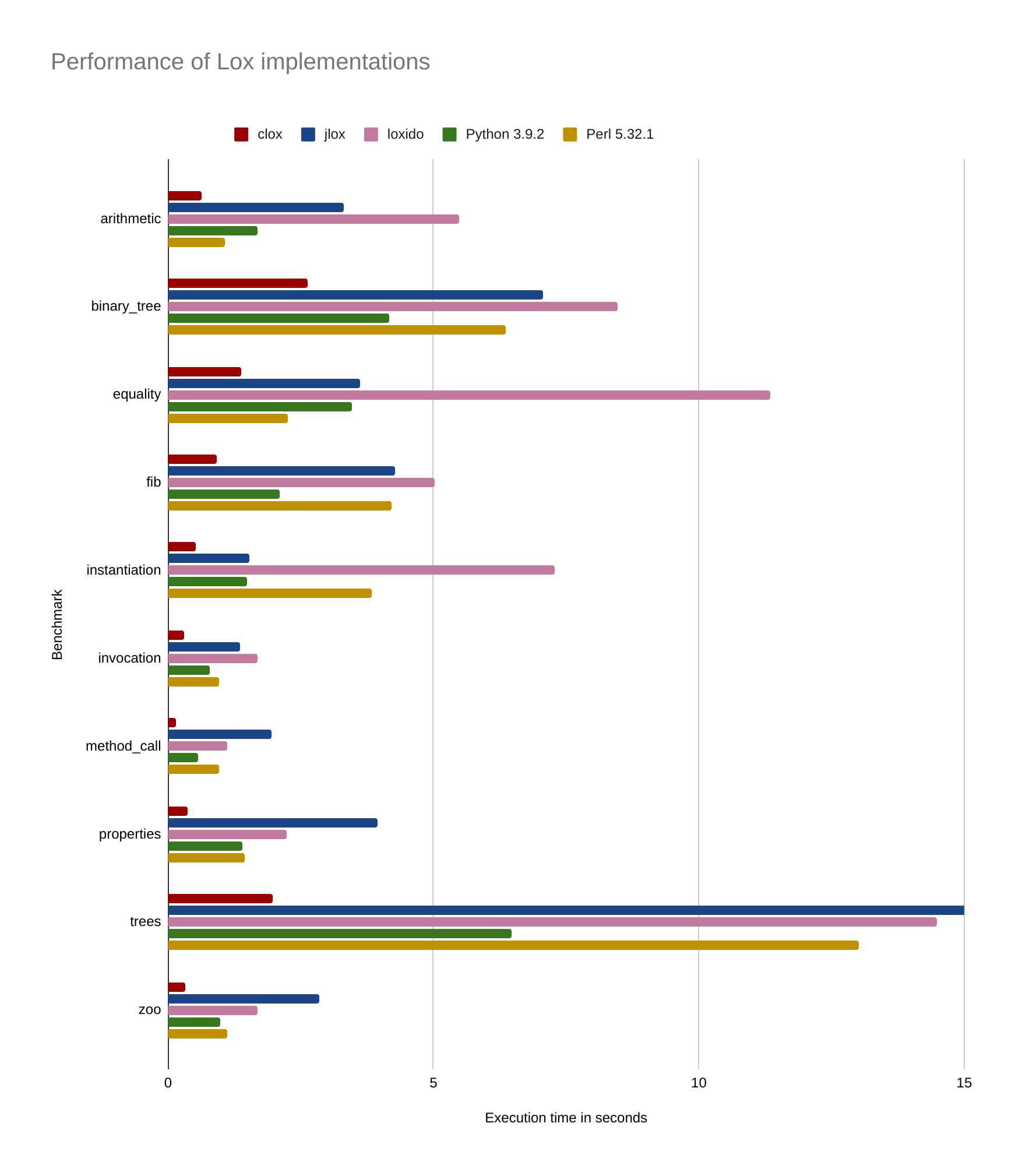
Not only is Loxido (my implementation) often several times slower than clox, but, in many cases, it’s even slower than jlox (the tree walking implementations written in Java)! After the initial shock, I realized that there was no other way than to start profiling and shave those times as much as possible.
The very first run of perf showed me a clear target to blame for my poor performance:
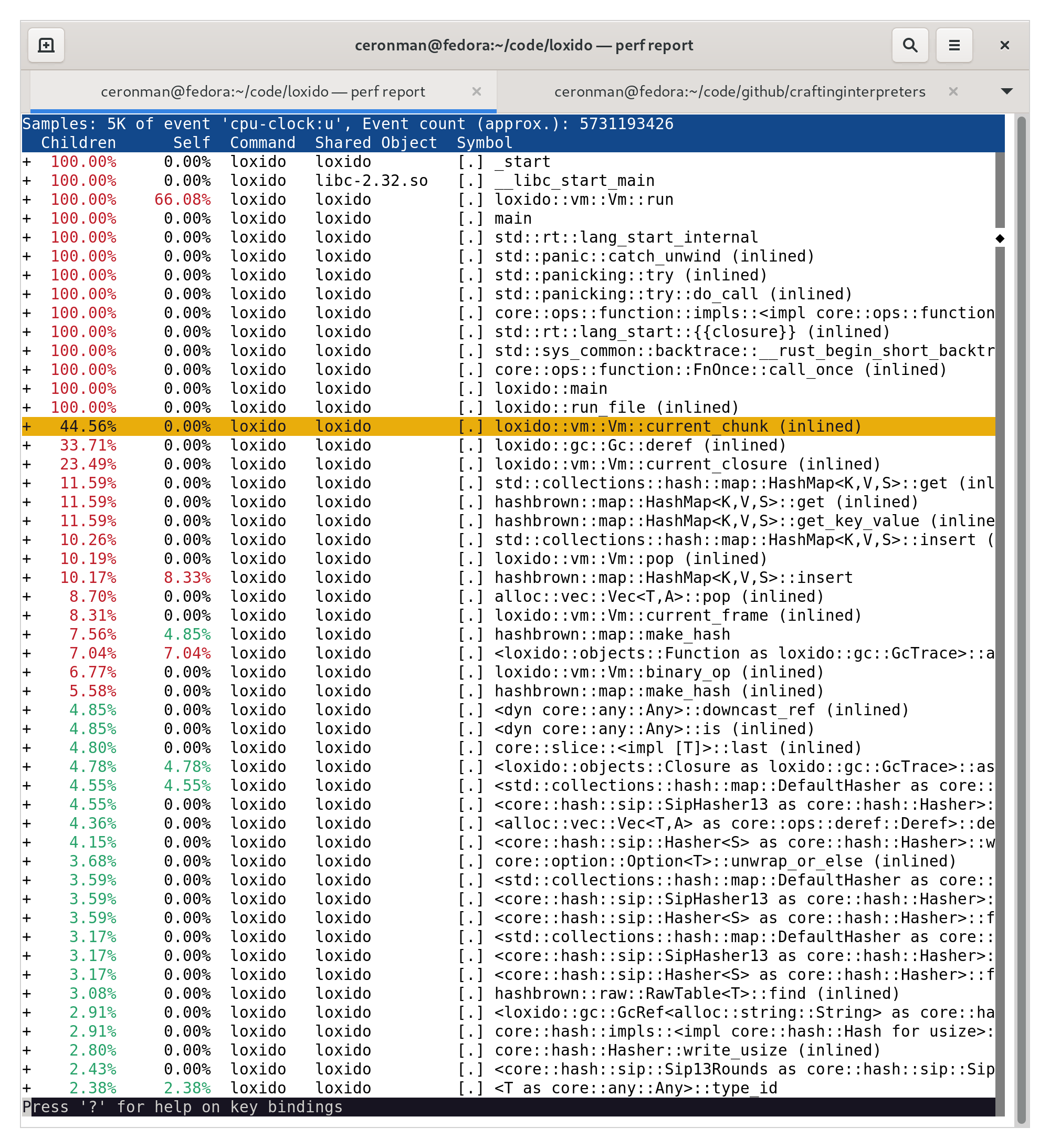
One of the problems was related to my GC implementation and the way I was dereferencing my index-based pointers. Using vector indices is slower than a regular pointer dereference. An arithmetic operation is needed to get the address of the element, but more importantly, Rust will always check if the index is out of bounds. For the vast majority of use cases, these extra steps are completely negligible, however when you have a VM that processes ~350 million instructions per second, and then you have to do three or four dereferences per instruction, then it shows. But even then, this was not the main problem. The big problem was with some of the workarounds that I had to add to please the borrow checker. I’ll try to explain this:
The core of a VM is basically a huge loop that increments the program counter (PC), grabs the next instruction and runs a big match expression. The PC is part of the current frame. The current frame has a reference to a closure object, which has a reference to a function object, which then has a reference to the chunk of bytecode that contains the instructions. In code it roughly looks like this:
loop {
let mut frame = self.frames.last_mut().unwrap();
let closure = self.gc.deref(frame.closure);
let function = self.gc.deref(closure.function);
let chunk = &function.chunk;
let instruction = chunk.code[frame.ip];
frame.ip += 1;
match instruction {
...
}
}
The first part of the loop is what was causing the problem. However, I don’t really need to do this on every single iteration. For most instructions, the active frame and chunk of bytecode remains the same. The current frame only changes when a function is invoked or when the current function returns. I could store this in a local variable as a reference and change it only on those instructions, for example:
let mut frame = self.frames.last_mut().unwrap();
let closure = self.gc.deref(frame.closure);
let function = self.gc.deref(closure.function);
let mut chunk = &function.chunk;
loop {
let instruction = chunk.code[frame.ip];
frame.ip += 1;
match instruction {
Instruction::Call => {
// update frame and chunk
}
}
}
This would increase the speed considerably. But there is a problem: Rust is not very happy about it. The way my implementation works is that the GC owns every object created. If I need an object, I could borrow it, and while I borrow it I’m also borrowing the whole GC. Because of Rust’s aliasing rules, if I decide to have a long-lived reference to the current chunk of byte code, I won’t be able to ever borrow mutably from the GC. So this causes a ton of borrow checker complaints. That’s why I ended up returning every borrow immediately. But this implies a ton of unnecessary dereferences.
Side note: A similar issue with the borrow checker that I often encountered is the one of interprocedural conflicts. There is a nice blog post by Niko Matsakis explaining this problem. I would love to see Rust improving in this area, as I see it as a major headache for beginners.
I tried quite some different approaches to work around this with safe Rust, but I failed on every single one of them. This was often frustrating because it required long refactorings and it was only until the end that I realized that it doesn’t work.
A simpler solution was to use raw pointers instead of references. This is easy to implement but requires unsafe blocks to dereference those two pointers. I ended up doing that and improvement was massive, with some benchmarks taking up to 74% less time.
After doing this I also decided to rewrite the GC and make the references wrap raw pointers instead of vector indices. This also required some unsafe code, but it also came with some nice speed improvements. And even better, it allowed me to get rid of a lot of boilerplate code because I could finally use Deref. So instead of doing things like
let closure = self.gc.deref(frame.closure);
let function = self.gc.deref(closure.function);
let chunk = &function.chunk;
I could simply:
let chunk = frame.closure.function.chunk;
This simplified a lot of code, and after these changes, my benchmarks improved considerably:
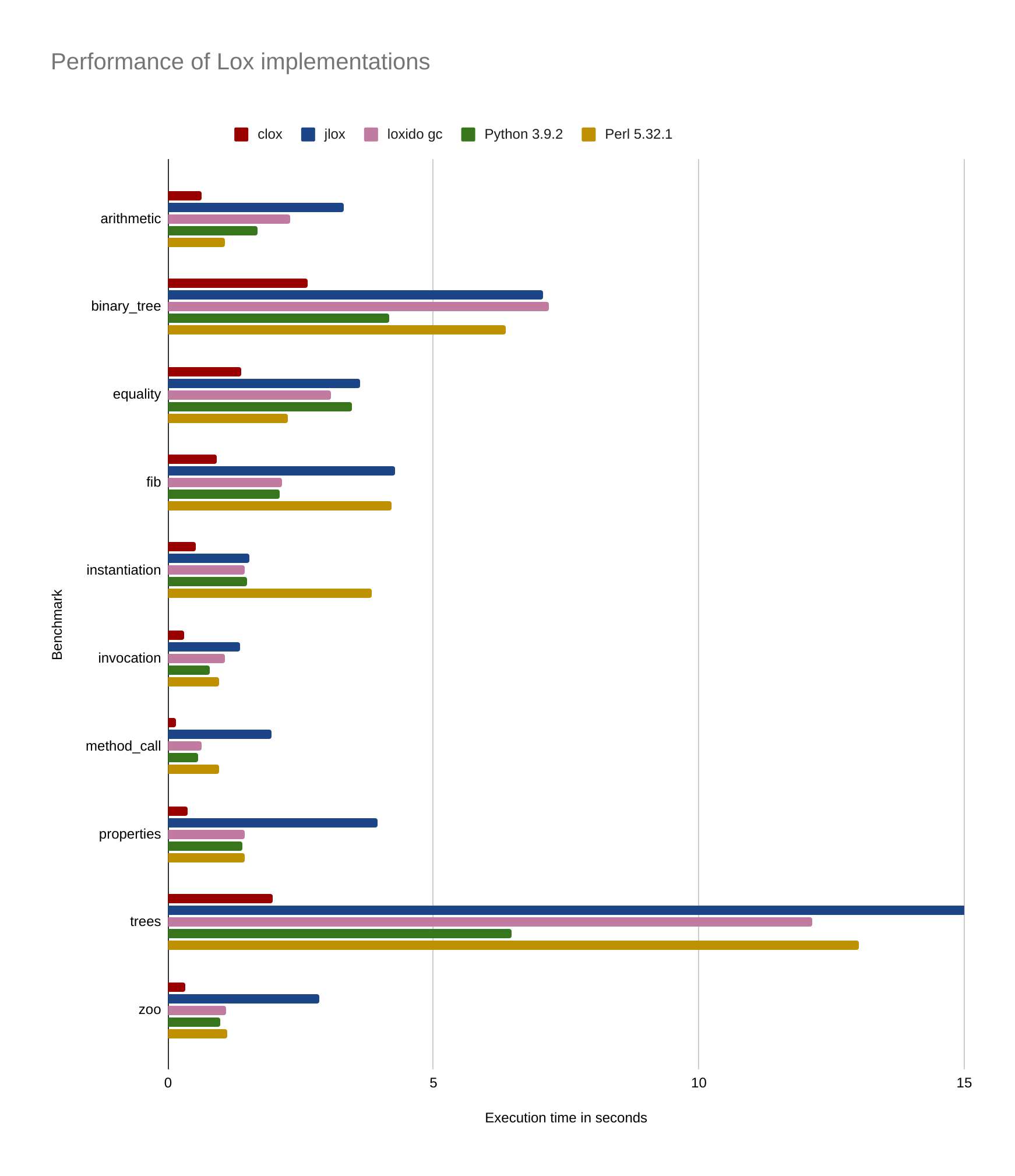
I was still far from the speed of clox, but at least I was already better than jlox and very close to Python and Perl.
Improving HashMap performance
The next thing that showed up in the profiler was HashMap operations. This was kind of expected. Like most dynamic languages, Lox uses hash tables heavily. They’re used to store global variables, interning strings, fields and methods. Any improvement in this area will definitely have a huge impact on the overall performance of the interpreter. In fact, the last chapter of the book, which is dedicated to optimizations, shows how a tiny change in the hash table code allows to shave up to 42% of the running time of a benchmark. That was impressive.
The easiest thing to try was to change the hashing algorithm. The HashMap implementation in Rust’s standard library uses SipHash by default, while clox uses FNV. I knew that SipHash is not that fast, so I thought I could get some easy wins replacing it. In Rust it’s very easy to switch hash function implementations. Just use a different constructor and the rest of the code remains intact.
I found a Rust crate that implements the FNV algorithm, but I also found one called aHash which claims to be “the fastest, DOS resistant hash currently available in Rust”. I tried both and indeed aHash gave better results.
With this tiny change I was able to shave up to 45% of the running time of some of the benchmarks. That’s super amazing for such a small change.
Later I found out that the Rust compiler uses another hashing algorithm called fxhash. Even though aHash claims to be faster than fxhash, given how easy it is to switch algorithms, I decided to try it. I was surprised to find improvements on all of the benchmarks. In some cases shaving up to 25% of time from the aHash results!
Side note: Don’t get super excited about these results. There is a very good reason why Rust uses SipHash by default. Algorithms such as FNV and fxhash are prone to algorithmic complexity DOS attacks. It’s probably not a good idea to use them for an interpreter. But given that this is not a real-world language, and I’m trying to match clox speed using FNV, I decided to ignore this fact for the moment. aHash, however, claims to be DOS resistant, which might be a very interesting option for a real language.
The improvements of switching hash function were quite significant. However, the profiler kept showing some performance bottlenecks caused by hash table operations. I also profiled clox and I found out that hash operations were not taking that much time there. I had to investigate more.
Rust’s standard library is using a very sophisticated hash map implementation called HashBrown. This is a port of Google’s SwissTables, a high-performance hash map implementation in C++. It even uses SIMD instructions to scan multiple hash entries in parallel. How could I ever improve on that? This seemed completely impossible.
So I decided to re-read the chapter of Crafting Interpreters dedicated to hash tables to see if I was missing any tricks. And this was the case indeed!
Unlike HashBrown, which is a general-purpose hash table implementation, the hash table in clox is tailored for a very specific use case. While HashBrown is generic, clox‘s Table only uses Lox strings as keys and Lox values as values. Lox strings are immutable, interned, and they can cache their own hashes. This means that hashing only occurs once ever for each string and comparison is as fast as comparing two pointers. Additionally, not dealing with generic types has the advantage of ignoring type system edge cases such as Zero Sized Data Types.
So I decided to bite the bullet and write my own hash map implementation in Rust closely following the code from clox. The results were very positive, I was able to shave time on most of the benchmarks, with a cut of 44% for the best case compared to HashBrown with fxhash. In the end, it was not a lot of code either. My hash map implementation is roughly 200 lines of mostly unsafe Rust.
Side note: Before writing my own hash table, I tried to mimic the same special conditions of clox tables using HashBrown. For example, I implemented PartialEq on GcRef
The price of dynamic dispatch
I was getting closer to the speed of clox, but there was a long way to go. One thing I noticed is that the time difference was much bigger in the benchmarks that ended up stressing the GC. The profiler showed that the tracing part of the garbage collection process was taking quite a lot of time.
As I mentioned before, I used trait objects to keep track of anything that should be garbage collected. I copied this idea from crates such as gc and gc_arena. Using a trait object allowed me to keep a list of all the objects, which is necessary for the sweeping process. The trait also would contain methods for tracing an object. Each object type had different ways of tracing. For example, a string should only mark itself, but an object instance should mark itself and its fields. Each garbage collected type should implement the GcTrace trait with the specific logic to trace it. Then, thanks to polymorphism, the tracing part of the garbage collector was as simple as this:
fn trace_references(&mut self) {
while let Some(object) = self.grey_stack.pop() {
object.trace(self);
}
}
As usual with polymorphism, this was short and elegant. I liked it a lot. However, there was a problem: This kind of polymorphism uses dynamic dispatch, which has a cost. In this particular case, the compiler is unable to inline the tracing functions, so every single trace of an object is a function call. Again, this is usually not a big problem, but when you have millions of traces per second, it shows. In comparison, clox was simply using a switch statement. This is less flexible but the compiler inlines it tightly which makes it really fast.
So instead of using a trait object, I rewrote the GC to use an enum instead. Then I wrote a match expression that would do the right tracing logic for each type. This is a bit less flexible, and it also wastes memory because the enum effectively makes all objects use the same space. But it also improved tracing speed considerably with up to 28% less time for the most problematic benchmark.
Side note: clox uses a different approach called Struct Inheritance. There is a struct that acts as a header and contains meta-information about each object. Then each struct that represents an object managed by the GC has this header as its first field. Using type punning, it’s possible to cast a pointer to the header to a specific object and vice versa. This is possible because in C structs are laid out in the same order as defined in the source. Rust by default doesn’t guarantee the order of the data layout, so this technique is not possible. There are ways to tell the Rust compiler to use the same data layout as C, which is used for compatibility, but I wanted to stay with Rust as intended.
Small unsafety speedups
There were other small details that made clox faster and were related to avoiding safety checks. For example, the stack in clox is represented by a fixed-size array and a pointer that indicates the top of the stack. No underflow or overflow checks are done at all. In contrast, in my Rust implementation, I was using a Vec and the standard push() and pop() operations which are, of course, checked. I rewrote the stack code to use a similar approach as clox and I was able to shave up to 25% of the running time.
Similarly, the program counter in clox is represented as a C pointer to the next instruction in the bytecode array. Increasing the PC is done with pointer arithmetic and no checks. In my Rust implementation, the PC was an integer with the index in the position in the bytecode chunk vector. Changing this to work as clox allowed me to shave up to 11% from the running time.
Getting speed-up improvements is nice, but the downside is that the code becomes unsafe. One of the best parts of Rust is its safety, and if you abandon it, it feels as dangerous like C but a bit uglier. But at least it’s nice that you can be very specific about what parts of your code are unsafe, this makes it much easier to debug when things go wrong.
Side note: How can clox live with all these unchecked pointer arithmetic? Well, the VM assumes that the bytecode will always be correct. The VM is not supposed to take any arbitrary bytecode, but only bytecode generated by the compiler. It’s the compiler’s responsibility to produce correct bytecode that would not cause underflows or overflows of the stack or frames. While the clox compiler does prevent a lot of these cases, it does not prevent stack overflows. The author intentionally decided to skip this check because it would require a lot of boilerplate code. Real-world interpreters using unsafe structures like these must absolutely do it though.
After the tweaks, my Rust implementation finally started to get really close to clox:
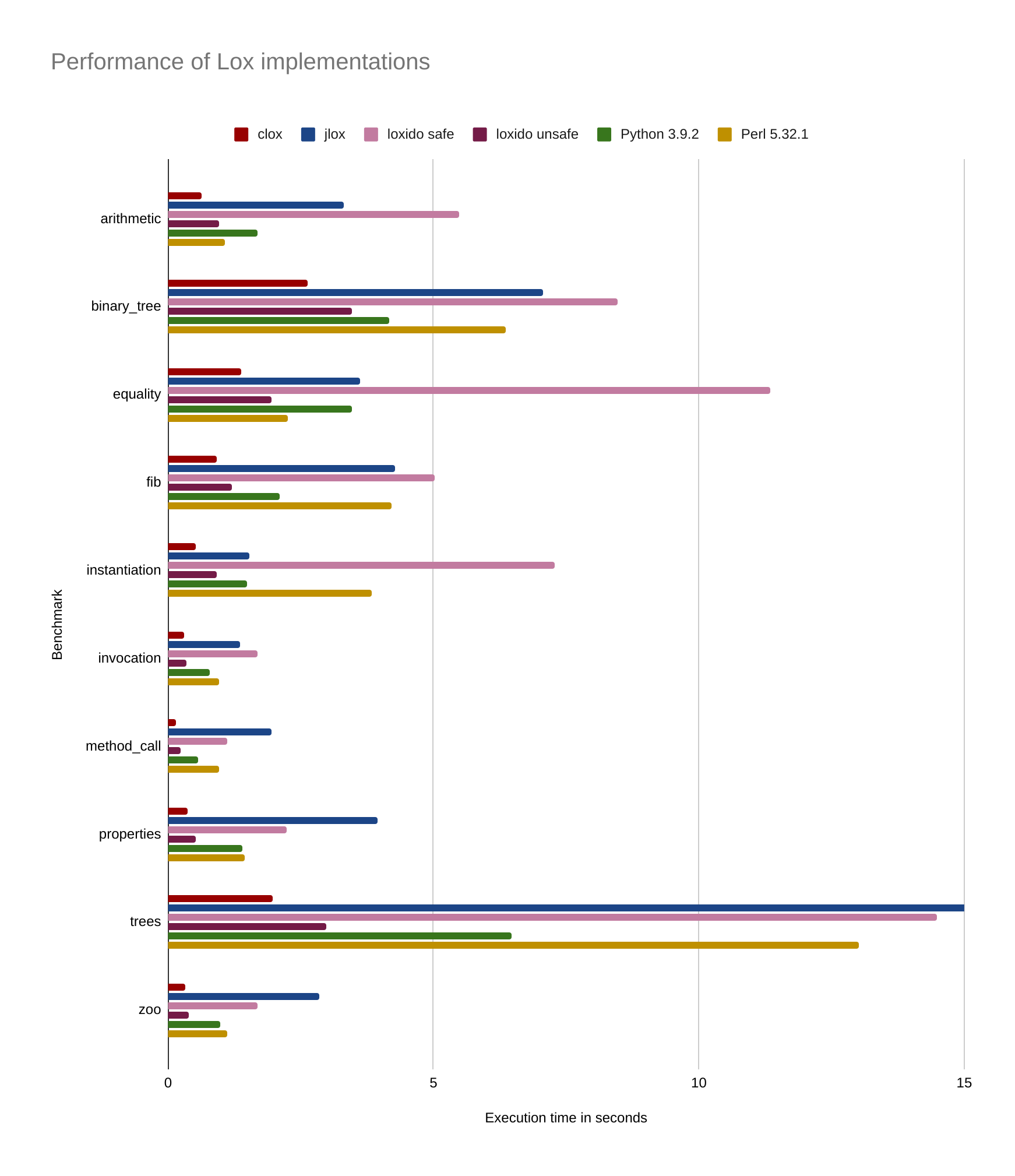
For most benchmarks, the running time of loxido is between 20% and 50% more than clox. It’s close, but not entirely satisfactory. Unfortunately, I reached a point where profiling my existing benchmarks doesn’t give me clear information about what parts of the code are making loxido slower.
I probably need to write some more targeted benchmarks. And I should start looking for clues beyond the profiler data, such as checking for cache misses, branch mispredictions and taking a look at the generated machine code. But this goes beyond my available time and knowledge, so I decided to leave loxido as it is here.
I have a few hunches of things that could improve performance. One is using struct inheritance to represent GC objects instead of using an enum. This would require changing the data layout of the structs to match C. The problem with using an enum is that a match operation is required on every dereference. I believe this match should be optimized out by the compiler, but I haven’t properly checked. But even then, struct inheritance is simpler and it will require fewer instructions in many places.
The second hunch is that perhaps using variable-length instructions might end up in a tighter bytecode that produces better cache utilization. I feel this is unlikely as the byte code is usually so small that I find it hard that this makes any difference. But I would like to have the time to test it anyway.
I also considered the fact that I compiled clox using GCC 10.3.1, while Rust 1.51.0 uses LLVM. I tried compiling clox using clang instead and indeed some benchmarks took up to 15% more time. But a few others were faster than the GCC version. So I discarded this as a big factor. My Rust implementation is consistently slower on all the benchmarks.
One more thing to consider was the impact of the NaN boxing optimization. Which I had zero plans to implement in Rust. I compiled clox without NaN boxing and compared the results. It almost made no difference. There were time variations of +- 5% across the benchmarks. So I don’t think this is a factor at all.
Final Thoughts
I enjoyed writing Rust very much and learning how to write a language VM with it. Crafting Interpreters is one of the most amazing technical books that I have ever read, I totally recommend it.
Rust can be frustrating sometimes, that’s undeniable. But Rust is also very rewarding. Besides the modern features in the language and its great tooling, I find the Rust community to be awesome. I know the hype can be annoying sometimes, especially when fans feel the need to jump into every single discussion to evangelize about the language, but, for the most part, the hype has a lot of positive things. The Rust community is vibrant, people are sharing knowledge all the time in the form of blog posts, discussions, tools, and libraries. The community is also very beginner-friendly, with tons of people willing to help even when the question has been repeated a thousand times in multiple places.
In some areas, Rust feels a bit half-baked. For example, dealing with variance in the type system is confusing and feels very hacky. The new allocator API is not there yet, which would have been very useful when writing my GC. And I think the borrow checker could be smarter in many cases. I would like to write in more detail about these things, but this post is already too long. Nevertheless, I think the language has very good prospects of improving and I’m glad the creators are not afraid of the language not being perfect. I look forward to keeping writing Rust and learning about it.
This is it! Thanks for reading!